How to build an advanced data analytics and reporting platform in 2 months
par Pierre Bittner | 01.01.2018Our MIFID 2 ice bucket challenge
RegTech Platform : 2 months, 4 guys, the worst period to start a new project (i.e Summer), how to implement a pilot for a financial market regulatory platform with innovative Big Data technology… Do you want to know if we took the challenge, if we succeeded and how? Read our report!Building a Regtech platform : How it all started ?
Back in summer 2016, we were asked to implement a pilot for a next generation platform (regtech platform) to implement the upcoming MIFID2 regulation along with the existing one (EMIR). It was a twofold challenge as the platform had to handle both the high data volumes generated by the new regulation perimeter (i.e all transactions executed by all market participants on listed markets in Europe and on most OTC products) and be able to monitor High Frequency Trading operations directly from the market exchange. And to further complicate matters,- We had only two months to achieve the full-platform
- That summer, we could only bring together a relatively small team of 4 people
Target audience :
This report is intended to:- Chief Technology Officer, Chief Innovation Officer, Chief Operating Officer, Chief Data Officer, Chief Digital Officer, Head of Compliance and Head of Risk in Financial Sector;
- Architect, Tech Leader and Data Engineer that must implement a Data-Centric architecture.
Télécharger la ressource
[contact-form-7 id="4759" title="Téléchargement : RegTech platform in 2 months"]
En savoir plus
The first chapter covers the functional requirements analysis that led to the architecture definition.
In this section, we go through the study of the business requirements that have driven us to the choice of the technical architecture. This analysis is key to achieve the development, in only two months, of a regtech platform capable of processing hundreds of Go of data per day for financial market monitoring. STEP 1: LOOK AT THE INPUT DATA STEP 2: CONSIDER THE VARIOUS USE CASES (“Data Pipeline”) STEP 3: MATCH THE REQUIREMENTS STEP 4: ARCHITECTURE CHOICE ZOOM ON THE KAPPA ARCHITECTURE We will explain how the Kappa Architecture, Apache Kafka and the choice of a recover upon failure capable stream processor and a reliable idempotent NoSQL datastore allowed us to fulfill all client’s requirements.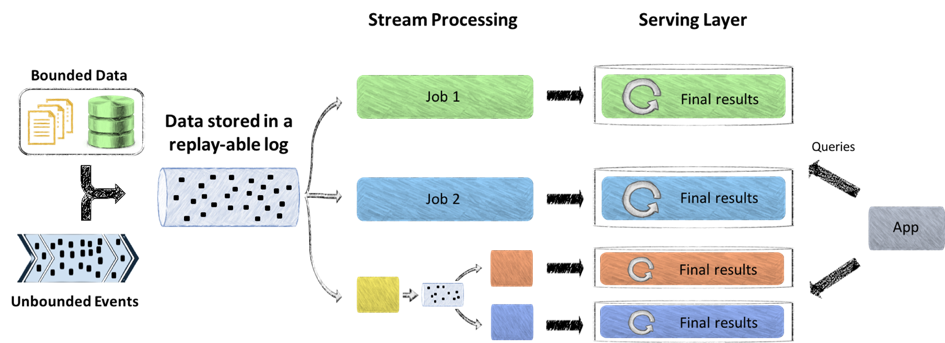
The second chapter covers the architecture that has been set up.
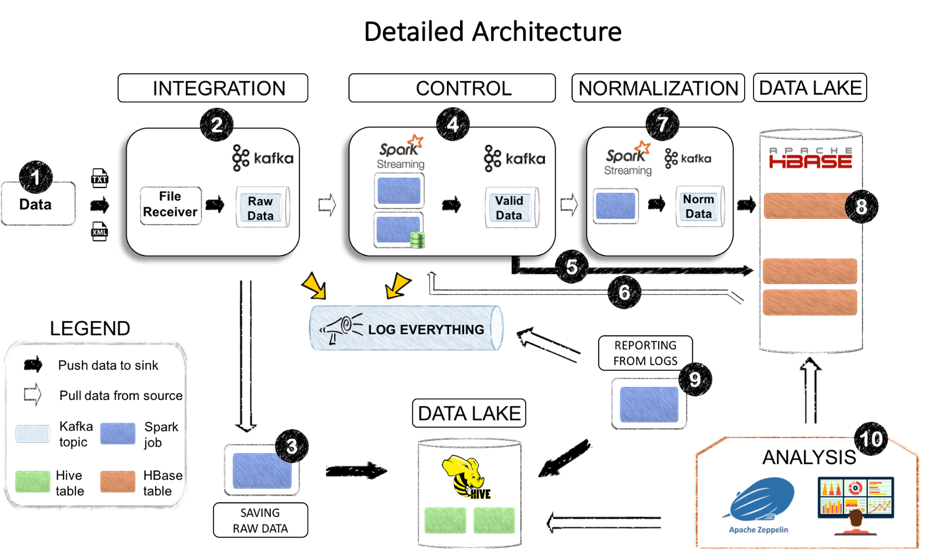
THE DETAILLED ARCHITECTURE IN 1O MAIN POINTS
- The input data
- Integration layer
- Saving RAW data
- Controller
- Functional Coherency / Reference Control
- Functional Coherency / Reference Check
- Normalization
- Data Storage
- Reporting
- Notebooks
PERFORMANCES AND KAPPA ARCHITECTURE IS LIFE
We run numerous sets of benchmarks on very different use cases to try to identify the most common bottle neck. We tell you if the pilot has been a success and what was the key factor of it.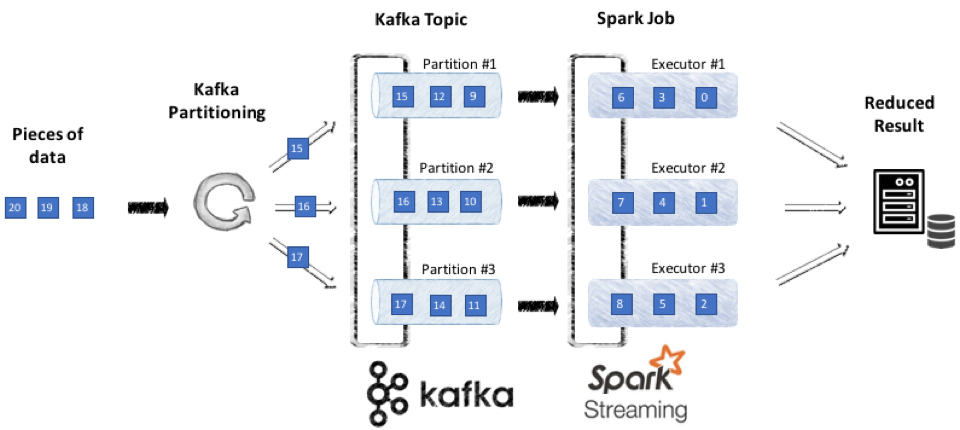 For years, we weren’t fully satisfied with big data architecture in the finance environment. Of course, in some context, the volume of data to process enforce the use of Hadoop solutions. But most solutions were based on distributed batch implementation of MapReduce paradigm which is slow, complex to setup and hard to maintain. These never fit to our vision of modern use cases in Finance.
With this report we want to demonstrate the pertinence of new architectures and their role in fostering the transition to digital finance.
For years, we weren’t fully satisfied with big data architecture in the finance environment. Of course, in some context, the volume of data to process enforce the use of Hadoop solutions. But most solutions were based on distributed batch implementation of MapReduce paradigm which is slow, complex to setup and hard to maintain. These never fit to our vision of modern use cases in Finance.
With this report we want to demonstrate the pertinence of new architectures and their role in fostering the transition to digital finance.